Query settings (available from Query Options on the Query ribbon) govern the operation of each query in a specific Discover report. They allow users to tweak the way a query is resolved and to improve performance. Once set, they drive the report and its subsequent usage in the platform.
The types of query settings available are:
Cache Options
The cache options govern whether a query result should be retrieved from the cache on Pyramid's servers (if available), or a new query should be run against the underlying data source every time. The main purpose of caching is to accelerate the re-use of the same query result set without re-querying the underlying data source for the same results.
From the Query ribbon in Discover Pro, click Query Settings > Cache Options > <Caching Option>.

There are three caching options:
- Model Default: Use the same caching options as the underlying data model. These options are set in the Admin Console or in the model definition.
- Disable Cache: Always re-query the underlying data source, ignoring any cached results from previous queries.
- Enable Cache: Avoid re-querying the underlying data source, use cached results if they exist.
Caching Mechanics
The caching mechanism does NOT store the query result permanently. Instead, it is held in memory in case the same query is required in the future. Since there are numerous complications with such a mechanism, there are many aspects of the platform that govern if and how queries are cached.
- The amount of time a query is held in the cache, if caching is enabled, is determined in the admin console:
- If the query cache setting is "0", the cache is effectively turned off globally.
- The cache is held in memory. If the server's memory starts reaching limits, queries may be released from the cache earlier than the specified time.
- If the data source is secured by user, the cache stores query results by user. This means that the same query executed by different users do not overlap in the cache.
- For data models designed in Pyramid, it's possible to determine the default caching mode to use for all queries run against it. By default, caching is enabled in all Pyramid models and by default, the cache settings in Discover reflect the settings made in the data model.
- For MS OLAP, Tabular, and SAP BW data sources, caching generally doesn't work when the model is security enabled. This is because there is no way to share results across a userbase. You can, however, enable caching when using the Model Default option, if the data model management properties in the data source manager are set as follows:
- The Data model has NO data-level security checkbox is selected.
- The Data model uses Real-time direct queries or ROLAP checkbox is clear (deselected).
- For a SAP Hana source:
- Where Hana has a Semantic layer (Calculation View / Analytic View), the caching details are as described for MS OLAP, Tabular, and SAP BW above.
- Where Hana is a Pyramid Model, the caching details are like any other SQL data source.
Query Cache in Present and Publish
Any queries included in Present and Publish reflect the settings made in Discover Pro for the content. There is an option in Present to ignore cache settings.
Row Limit
The row limit defines the maximum number of rows that will be returned in the query results. For more information, see Row Limit.
Note: There may also be a MASTER query limit set by the administrator in the Admin Console. Where this is the case, Pyramid uses the lower of the two limits. For more information, see Query limits.
Optimization Settings
These settings govern the operation of the query in a specific Discover report. Choosing these options alters the construction of the underlying query with the aim of improving performance or behavior given your modeling.
Although the objective of changing these options is to improve performance, you should be aware that, because of the complex interactions of your model, your data source , and the changes to the underlying query, your changes may not have that effect. You should, therefore, test any changes to your optimization settings extensively.

The preceding image shows the Optimization Settings for Microsoft Multidimensional and Tabular. Other options are shown for other data sources.
Tip: When you select the optimization options below, you alter the construction of your underlying query. You may, therefore, find it helpful to view the changes to your query in the Query Text dialog. For more information, see Performance dialog.
SQL based data sources
- Optimize: Enables the SQL engine to join multiple queries together to make a query run more efficiently. If this option is not selected, the Pyrana engine runs smaller but more fragmented queries. This feature is enabled by default for all new discoveries.
- Sub Query Mode: Instructs the query engine to use sub queries. This enables the Pyrana engine to make use of the ANSI SQL sub query functionality. This can be used to optimize a query execution to run multiple logical steps in one SQL query.
Microsoft Multidimensional (OLAP) and Tabular
Microsoft's MDX engine has undergone numerous changes since its inception. Due to differences in versions, differences between Multidimensional and Tabular, as well as differences in cube / model design, there are some elements of the MDX query construction that need to be modulated. The following settings will allow advanced users to tweak how the MDX query is executed.
- Optimize: Only return elements that have a value for the measures we are interested in (non-empty logic). Applies to filters, N-of-Ns, and sort operations, and is intended to improve processing times.
- Measure Optimization: Enables 'non-empty' logic on measure selections to improve processing times. This feature will not work in some cube scenarios.
- Context Heuristics: Applies 'EXISTING' functional logic to various operations to force the injection of context values into different parts of the query when using two or more attributes from the same dimension. This feature is used to correct logical errors in Microsoft's MDX engine.
- Auto-include Calculated Members: Enables all functional queries to include server-defined custom members in results.
- Sub Query Mode: Use sub queries in MDX when making multiple background "
where" selections. This is typically more efficient than the default multi-select aggregation, but it cannot be used universally since any custom filters are stripped from the query (custom filters are, effectively, ignored). - Use Explicit Lists: Explicitly declare sets in the "
with" statement for any list or multi-select filter used in the Discover report, even where the set is only used once. Where this optimization is not applied, sets are only declared where they are used multiple times. - Remove Filter Scoping: Removes the Scope Isolation function from the filter query.
- Cross Filtering: If a regular filter is set in one report and a context-based multi-select filter based on a dynamic list is also selected, the elements in the second filter will be based on the selection in the first filter. This option is typically enabled by default, for backwards compatibility. Clear selection of this option to disable cross filtering in this scenario.
SAP BW
- Sub Query Mode: Use sub queries in MDX when making multiple background "
where" selections. This is typically more efficient than the default multi-select aggregation, but it cannot be used universally since any custom filters are stripped from the query (custom filters are, effectively, ignored). - Optimize: Only return elements that have a value for the measures we are interested in (non-empty logic). Applies to filters, N-of-Ns, and sort operations, and is intended to improve processing times.
- Use Explicit Lists: Explicitly declare sets in the "
with" statement for any list or multi-select filter used in the Discover report, even where the set is only used once. Where this optimization is not applied, sets are only declared where they are used multiple times. - Shard Measures: When returning measures, this option separates the queries into individual "sharded" queries that are handled separately from one another. Use this option to improve parallel processing performance on older BW systems, that do not necessarily run queries efficiently.
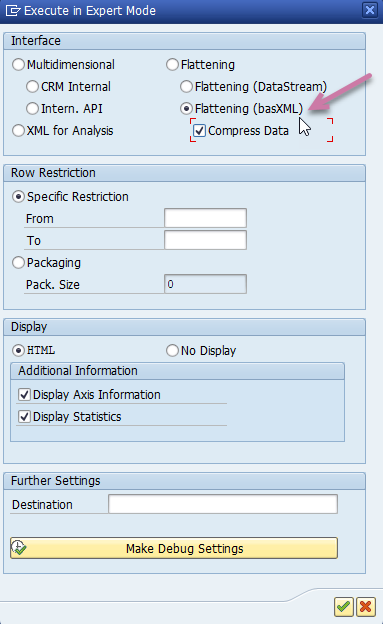
- Execution Mode: Where the Allow for Optimized Execution Modes option is selected for your SAP BW data source, you can select one of the Execution Modes. These options map to the SAP BW MDX Execution settings as follows:
- Regular maps to Multidimensional.
- Optimized maps to Flattening.
- Optimized Compressed maps to Flattening (basXML) with the Compress Data option selected.
- Cross Filtering: If a regular filter is set in one report and a context-based multi-select filter based on a dynamic list is also selected, the elements in the second filter will be based on the selection in the first filter. This option is typically enabled by default, for backwards compatibility. Clear selection of this option to disable cross filtering in this scenario.
In the following screen shot, the equivalent selections to Optimized Compressed have been selected (purple arrow):